计算机论文发表-基于实验数据处理平台对海量实验数据的研究
摘要:在计算机数据处理中,会遇到处理海量实验数据的问题。以往处理方式大多数以提升硬件成本为主。这使得研发成本也随之提高。针对这一现象,本篇计算机论文发表利用Hadoop平台,设计并实现了实验数据处理平台。

关键词:云计算;Hadoop;实验数据
1引言
现代科学实验过程中,处理的数据量越来越大。这些数据往往都有海量、复杂等特点。云计算正是在这样的时代背景下产生的。云是指分布式计算、并行计算、效用计算等传统计算机和网络技术发展融合的产物[1]。本文针对目前海量实验数据的处理问题,选用Hadoop平台作为基础框架,充分利用云技术,设计并实现了该实验数据处理平台。
2Hadoop简介
Hadoop能够对海量数据进行分布式处理,其主要包括分布式文件系统、MapReduce编程模型及HBase分布式数据库等。该平台能为应用程序提供一组稳定、可靠的接口和数据服务。因此用户可以在不了解底层细节的情况下,开发分布式程序,充分利用集群进行高速运算和存储[2-3]。
3系统设计
3.1系统框架设计
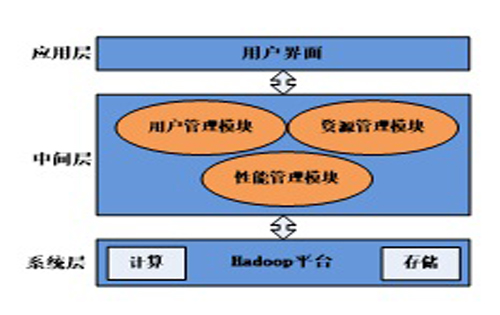
本篇计算机论文发表所说的平台采用三层体系架构,架构模型如图1。应用层是系统与用户进行交互的上层界面,用户可以向系统发出计算请求,当系统接收到请求后,将该用户的请求信息向其他层转发,最后将计算结果反馈给用户。中间层位于应用层与系统层之间,具有承上启下的作用。系统层是系统的核心数据处理层,主要是通过MapReduce和HDFS实现分布式计算及存储。
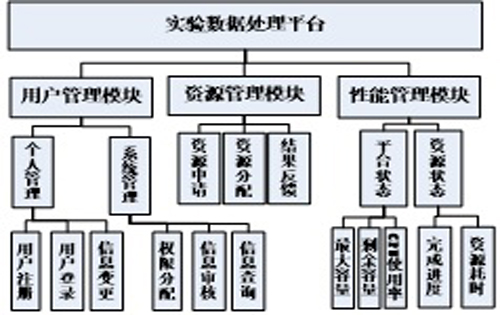
图1系统架构模型图2系统功能模块
3.2系统功能模块设计
从实际业务角度考虑,设计系统功能结构如图2:
1. 用户管理:分成两个子模块,其中个人管理模块实现用户对本人信息的管理;系统管理员模块实现对用户的管理。
2. 资源管理:主要实现系统资源合理分配等功能。
3. 性能管理:主要实现对系统性能的监管。
4.系统实现
4.1Hadoop环境配置
本系统共使用四台主机A、B、C、D,操作系统均使用RedHat4.8版本、Java使用的版本是jdk1.6.0_14,Hadoop使用1.0.3版本。将主机A设置为NameNode节点,其他三台主机设置为DataNode节点。IP配置如图3:
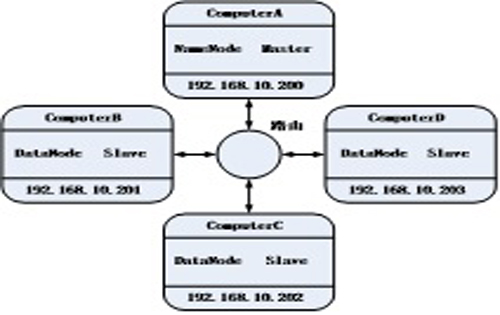
图3IP配置示意图
配置步骤:
1. 安装JDK、配置环境变量,首先在主机A上安装JDK,其他三台主机也按照同样的方法安装。
(1)安装jdk1.6.0_14
[root@ComputerA~]#chmoda+xjdk-6u14-linux-x64.bin
[root@ComputerA~]#./jdk-6u14-linux-x64.bin
(2)将JDK目录移动到/usr/java目录下
[root@ComputerA~]#mkdir/usr/java
[root@ComputerA~]#mvjdk1.6.0_14/usr/java
(3)配置java环境变量,修改bash_profile文件
export JAVA_HOME=/usr/java/jdk1.6.0_14
export CLASSPATH=$JAVA_HOME/lib/dt.jar$JAVA_HOME/lib/tools.jar:
export PATH=$JAVA_HOME/bin:$PATH

2. Hadoop平台的安装与配置:
(1)安装
[root@ComputerA~]#tar-zxvfhadoop-1.0.3.tar.gz
[root@ComputerA~]#cp-rhadoop-1.0.3hadoop
(2)配置
①设置环境变量:修改/root/hadoop/conf目录下的hadoop-env.sh文件。
export JAVA_HOME=/usr/java/jdk1.6.0_14
②设置Master节点:修改/root/hadoop/conf目录下的masters文件。
③设置Slaves节点:修改/root/hadoop/conf目录下的slaves文件。
④设置HDFS地址、端口:修改core-site.xml文件。
⑤设置Name镜像文件存放目录:修改conf/hdfs-site.xml文件。
⑥设置数据存放目录:修改conf/mapred-site.xml文件。
当Hadoop平台在主机A上安装、配置成功后,将主机A上的Hadoop复制到其他主机上,这样四台主机上的Hadoop的目录结构都是相同的,配置文件都在/root/hadoop/conf/目录中,程序都在/root/hadoop/bin目录中。
-
 计算机论文发表-基于KVM的桌面虚拟化架构的应用研究计算机论文发表-基于KVM的桌面虚拟化架构的应用研究 摘 要: 本篇 计算机论文发表 在服务器虚拟化技术的基础上,提出了一种基于KVM服务器虚拟化技术的
计算机论文发表-基于KVM的桌面虚拟化架构的应用研究计算机论文发表-基于KVM的桌面虚拟化架构的应用研究 摘 要: 本篇 计算机论文发表 在服务器虚拟化技术的基础上,提出了一种基于KVM服务器虚拟化技术的 -
 计算机网络技术论文发表-工业物联网安全体系架构研究计算机网络技术论文发表-工业物联网安全体系架构研究 摘要:随着物联网技术的发展,物联网在工业领域的应用也日益广泛,但物联网的安全隐患为其在
计算机网络技术论文发表-工业物联网安全体系架构研究计算机网络技术论文发表-工业物联网安全体系架构研究 摘要:随着物联网技术的发展,物联网在工业领域的应用也日益广泛,但物联网的安全隐患为其在 -
计算机论文发表-基于实验数据处理平台对海量实验数据的研究在计算机数据处理中,会遇到处理海量实验数据的问题。以往处理方式大多数以提升硬件成本为主。这使得研发成本也随之提高。针对这一现象,本篇计算
-
 计算机信息管理论文-校园上网安全管理的几点建议和对策本篇计算机信息管理论文对如何加强校园网用户上网行为安全管理问题进行了探讨,首先首要分析了安全管理存在的问题,在此基础上就如何进一步加强安
计算机信息管理论文-校园上网安全管理的几点建议和对策本篇计算机信息管理论文对如何加强校园网用户上网行为安全管理问题进行了探讨,首先首要分析了安全管理存在的问题,在此基础上就如何进一步加强安
